
kaldi语音识别实战pdf
导读
本文将介绍语音识别框架kaldi中提出的chain model语音识别系统,文章会先介绍HMM-DNN语音识别系统以及语音识别中的区分性训练作为铺垫知识,最后再重点介绍chain model的内容。
HMM-DNN语音识别系统
1.语音识别的公式化表达

语音识别解决的是由音频转文字的任务,那么最优的词序列(即句子)是由解码器[1]在限定的解码词序列空间内,搜索到的使得P(O|W)和P(W)乘积最大的词序列W。P(O|W)是由声学模型给出的,描述音频声学特征O和词序列W的声学模型的匹配程度的概率。P(W)是由语言模型给出的,在语言模型中该序列的语言学概率。可以看到,我们最终的识别结果是在语言学和声学的双重限制下得到的最优结果。
2.语音识别的流程图表达

上面的流程图相较于公式更加形象,红色部分是解码器,解码器会在解码图(可以理解为语言模型限定的解码空间)中搜索所有可能的路径(即由单词序列组成)。图中给出的例子是“你好”,在解码图中“你好”序列会被分解为音素序列“n i3 h ao3”的HMM序列,由声学模型计算音频声学特征和HMM序列的匹配程度,即声学得分(acoustic score),再由语言模型给出路径的语言学得分(language score)。最终,解码器会在尝试解码空间中诸多路径之后给出一个最优的识别序列。
3. HMM-DNN语音识别系统
HMM-DNN[2]描述的是声学模型的建模方法,即用HMM(隐马尔可夫模型)来描述音素状态之间的跳转,DNN(神经网络)来给出音素状态的发射概率。在解码过程中,声学模型负责给出一条状态序列S(S1,S2,…,ST)和对应声学特征序列的一个匹配概率P(O|S)。公式化表达如下:
上式中的P(St|St-1)是由HMM的状态转移概率来给出的,P(Ot|St)在HMM-GMM模型下,是直接输入声学特征Ot到St状态的GMM来给出的。那么在HMM-DNN模型下,P(Ot|St)是由输入声学特征Ot到神经网络然后经折算之后得到的。
DNN是如何做到替代GMM的呢?无论是在HMM-GMM[3]还是HMM-DNN系统中,每一个音素都由一个三状态的HMM来建模,如下图所示:
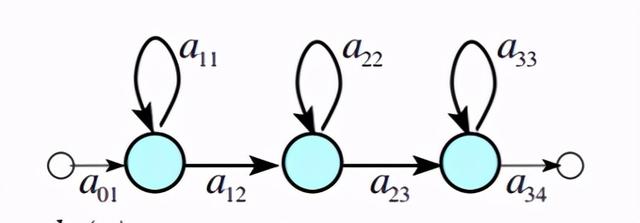
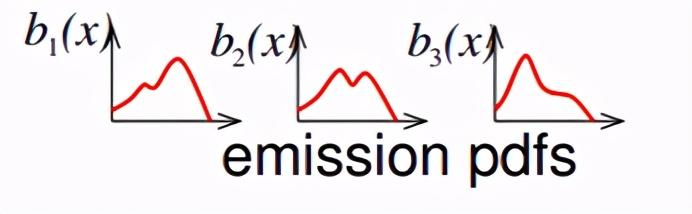
蓝圈表示此HMM的三个状态。在HMM-GMM中,每个状态的发射概率用GMM来描述,如下为上面HMM的三个状态分别对应的三个GMM:
我们在建模过程中,引入了三音素的概念,即对于一个音素,考虑其所处的上下文,前/后各一个音素,成为三音素。那么比如下图的四个HMM-GMM模型,他们都是音素iy的声学模型,但是区别是上下文音素不同。第一个是上下文音素为s和l的音素iy的声学模型,第二个是上下文音素为f和l的音素iy的声学模型,第三个是上下文音素为t和n的音素iy的声学模型,第四个是上下文音素为t和m的音素iy的声学模型。
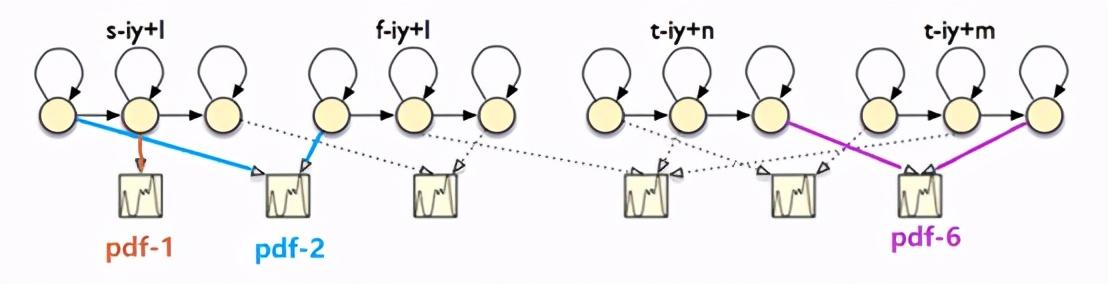
引入三音素模型会导致参数量的暴涨,我们并没有足够的数据来对每一个三音素的参数进行充分的训练。因此引入三音素模型的同时,也引入了状态绑定的概念[4],即经绑定后的音素状态,共享相同的GMM,GMM又被称之为pdf(probability density function),在kaldi中会给每个pdf编一个号,即pdf-id。所以说经过绑定后的状态会拥有相同的pdf-id。上图给出的四个iy的HMM模型便有共享pdf的情况,蓝色箭头表示:s-iy+l和f-iy+l音素的第一个状态的发射概率都是有pdf-2来描述的,紫色箭头同理,棕色箭头表示s-iy+l音素的第二个状态的pdf是自己独有的,不和其他音素共享。
那么如果是HMM-DNN系统呢,我们并不是为每一个状态训练一个神经网络,而是所有状态的发射概率都用一个神经网络来给出。因此,神经网络的输出节点数就必须等于HMM-GMM建模的GMM个数,即pdf-id个数。这样再输入指定特征后,就可以从指定的DNN输出节点位置,拿出任何想要的pdf-id概率。但是这个概率和把声学特征带入GMM给到的概率在数学上并不是同一个概率。GMM给出的概率就是P(Ot|St),因为我们是通过在St的状态查询到他的发射概率的pdf-id,然后带入这个pdf-id对应的GMM求得概率。而DNN给出的概率是P(St|Ot),因为我们是先把特征输入DNN,再从想要的pdf的指定节点位置去找概率。综上,DNN输出的概率还是不能直接拿来替换GMM的,而是需要用贝叶斯公式做一个折算,如下:
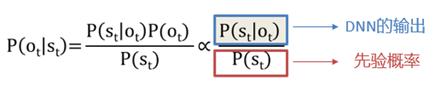
也就是说,在实际用的时候,要用DNN的输出概率除以St状态的先验概率,才可以用在声学分数的计算中。
HMM-DNN系统的训练过程如下所示:
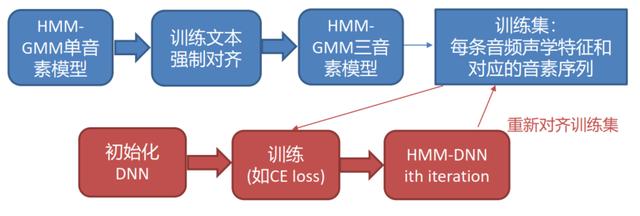
首先是需要训练一个HMM-GMM单音素模型,然后对训练文本做强制对齐,再扩展到训练一个HMM-GMM三音素模型,再将训练集做强制对齐。强制对齐指的是:将训练集中的每条音频,利用标注文本,解码得到每一帧对应的音素状态。下面是一个简单的例子:

上面的例子中,utterance1这条音频对应的标注文本是:没有。标注人员只能精确到句子级别,而我们的训练需要帧级别的标注,所以需要强制对齐。那么强制对齐后的形式是一些数字序列,每个数字表示hmm状态的id,我这里用方括号[]把一个音素的状态都给括起来,这样便于观察。那么如果我用这些id去找到对应的音素,便是最后一行的形式,可以清楚的看到就是“没有”单词序列对应的音素序列“m ei2 ii iu3”。
那么用HMM-GMM把所有训练数据做了强制对齐之后,即给训练数据打上了帧级别的标签,我们接下来就可以用来训练神经网络了。每一帧都有一个label,对应DNN的一个输出节点,相当于一个多分类问题,因此这里用交叉熵作为损失函数来训练DNN就可以了。DNN被训练一定的轮数之后,可以将训练集用HMM-DNN系统来进行重新的强制对齐,然后再迭代训练DNN。
语音识别区分性训练
1.区分性训练公式化表达
区分性训练[6]是一种针对声学模型训练的策略,是相比于最大似然训练较高阶的内容。这两种训练公式化的表达如下:

对于HMM-GMM系统而言,在训练时需要更新的参数是HMM的状态转移概率和每个GMM的各分量权重、协方差矩阵、均值向量,参数更新方法是EM算法(Expectation-Maximization Algorithm) [5]。对于HMM-DNN系统而言,在训练时需要更新的参数是HMM的状态转移概率矩阵和DNN的参数,DNN的训练一般使用交叉熵损失反向传播进行。上面提到的这两种更新参数的方式,实际上都属于最大似然训练的范畴。用通用的数学公式表达就是表格第一栏的形式,θ表示声学模型的所有参数,u指的是单条音频,Wu指的是音频u的标注文本,Ou是音频u的声学特征,最大似然训练的目的是给定标注文本的情况下,找到最大化似然概率的参数θ。
从表格第二行可以看到区分性训练的表达式,经过贝叶斯定理的展开后,可以清晰的看到整个表达式分成了分子和分母两部分。那么分子部分,和最大似然训练一样,都是在标注文本上的概率计算。差异性最大的便是分母部分,分母部分的计算是汇总了所有可能词序列的概率。
借助公式,我们可以看到最大似然训练和区分性训练思想上的不同。最大似然训练仅考虑最大化正确路径概率,区分性训练考虑的是最大化正确路径和所有其他路径的概率比值,也就是说我不仅要正确路径概率要大,而且要尽可能的比其他路径都要大。同时,还能看到区分性训练的公式中出现了P(W)的身影,也就是意味着,我们的训练还考虑到了语言学信息,这也是区分性训练更加优秀的原因。
区分性训练会有诸多变体,如MMI(Maximum Mutual Information),MPE(Minimum Phone Error)。但他们的思想都是一致的,我们这里只介绍MMI区分性训练。MMI区分性训练的损失函数定义如下:
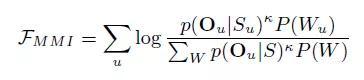
Su指的是将文字序列拓展开得到的音素状态序列,к是一个常量。那么分子部分的计算依然是在标注序列上,分母部分的计算中有∑w部分,意味着我们要由解码图中所有可能的词序列计算得到。
2.区分性训练的实际应用
上面提到的MMI区分性训练的损失函数计算方式,其中分母是由解码图中所有可能的词序列计算得到,这里先简单介绍下解码图。解码图是语音识别中用来约束解码器的词序列搜索空间的WFST,解码器从解码图的初始状态出发,不断的尝试可以走的路径,同时计算声学特征在该路径的得分并和该路径的语言学得分做整合,直到用尽最后一帧特征。那么可以知道,解码图是一个非常大的搜索空间,因此我们在计算区分性训练的损失函数分母部分时,会面临的问题就是巨大的计算开销。所以一般来说,不会在解码图上去做搜索计算,而寻求一种近似方法,既能减少计算开销,又能尽可能的逼近真实值。这里我们引入lattice的概念,lattice就是上面说的解码走完之后,保留的所有有效路径形成的图,一般会保留多条优势路径,而不是就一条。这样分母的计算,就可以在每条音频的在大解码图中搜索得到的lattice小图上完成计算,大大节省了计算开销。
3.区分性训练流程
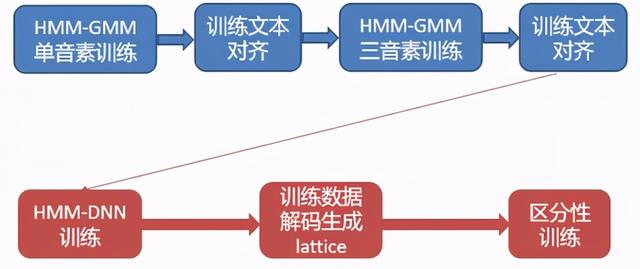
上图便是对HMM-DNN声学模型做区分性训练的流程,同样也是需要蓝色部分即HMM-GMM模型的训练以及对训练数据的强制对齐,然后对HMM-DNN做最大似然训练,训练好之后,生成训练数据的lattice作为区分性训练的准备,最后一次才进行区分性训练。
chain model
1. chain model和区分性训练、HMM-DNN的关系
前面两部分讲述了HMM-DNN和区分性训练的知识,这些都是了解chain model[7]的预备知识。那么chain model和这二者之间的关系是什么呢。首先chain model的声学模型结构就是HMM-DNN,标准的chain model用的神经网络是TDNN[8],chain model所用的HMM拓扑结构和标准的三状态HMM也有明显的不同。chain model的训练策略采用的就是前面所介绍的MMI区分性训练,但是chain model没有采用前面近似的损失函数计算方法,而是用自己独有的方法来计算。
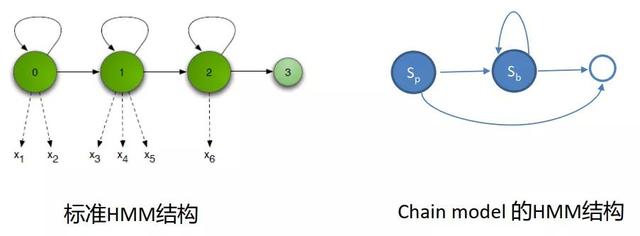
2.chain model的tricks
chain model 采用的HMM拓扑结构,如图所示,是一种特殊的单状态HMM。先看下左边的标准三状态HMM的拓扑结构,0/1/2表示此音素三个状态的序号,在这种拓扑结构下,因为每个状态都存在自跳弧,所以每个状态可以出现任意多次,这样的话可能出现的音素状态序列会是下面的形式:S0,S0,S1,S1,S1,S2,S2。在chain model的HMM拓扑结构中,用Sp状态来表示音素,如果之后连续出现此音素,则是用Sb这种空状态来表示,可以在图中看到Sp状态只能往前跳,不存在自跳弧,这样的话可能出现的音素序列是下面的形式:Sp,Sb,Sb,Sb,Sb。所以说chain model的建模颗粒度是音素级别的,而非音素状态级别的。
chain model所采用的神经网络为TDNN(如下图),一般的HMM-DNN声学模型,对于每一帧的声学特征,都会给出这一帧在不同的音素状态上的概率,TDNN也不例外,即多少帧特征就会有多少帧的输出。chain model的特殊点在于,他没有把TDNN的每一帧输出都用来做解码,而是采用跳帧的方式,即每隔三帧取一帧的输出给到解码器做解码。HMM为了适应这种跳帧,放大了建模颗粒度,就是我们前面介绍的那样,即使这样跳帧,也不会丢掉音素。这样跳帧带来的好处就是,解码的耗时可以比一般的HMM-DNN减少三分之二。
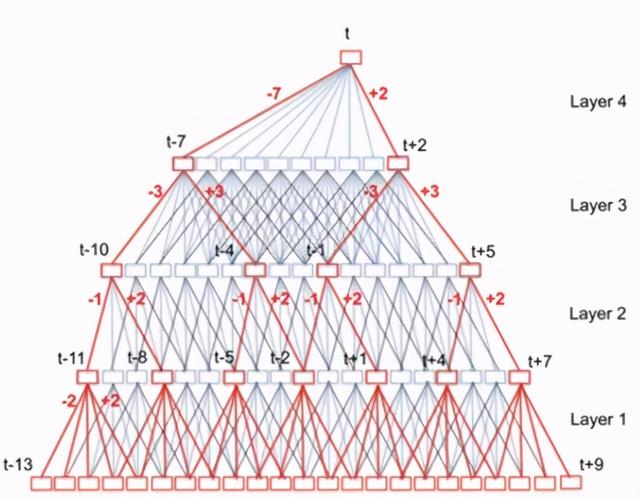
chain model采用的训练策略是MMI区分性训练,核心点还是损失函数的计算方式,如下图:
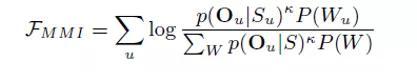

我们上面讲到损失函数计算方式是,分子由音频的标注文本序列计算,分母是由lattice来做近似计算。chain model对损失函数的计算和之前完全不同,首先分子是在标注文本的解码空间生成的lattice上做计算,分母的计算则是由真正的解码图来算,并非和之前一样,用lattice的近似。那么这里又回到了之前的问题,在真正的解码图上做计算实际开销很大,所以chain model所用的解码图并非是词级别的,而是音素级别的解码图,所以用的语言模型也是音素级的语言模型,这样就减少了计算量。为了减少计算量的另一个措施便是,抛弃之前的上中下文音素建模的假设(即三音素triphone),采用了前后相关音素bi-phone。
chain model的训练过程是在GPU上进行的,为了配合GPU的并行加速训练,会在准备阶段就把训练数据切分成固定大小的chunk,一般为(0.9s/1.2s/1.5s)。同时为了避免过拟合,引入了cross-ectropy作为第二个训练的损失函数。
3.chain model训练流程
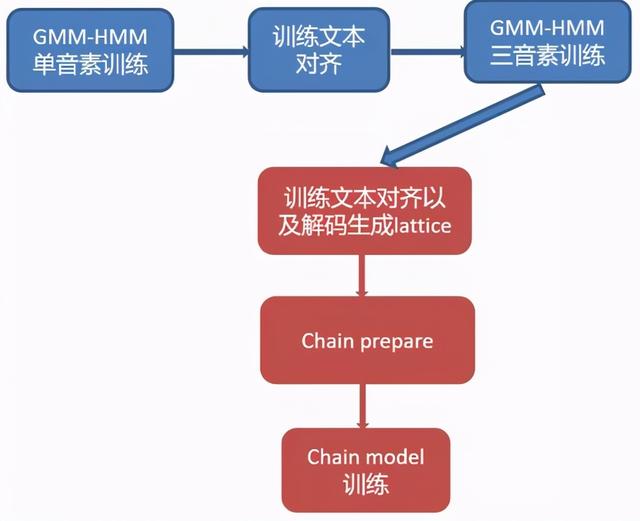
上面是chain model训练流程的一个展示,同样的还是需要GMM-HMM来作为一个启动的模型,来对我们的训练数据打上帧级别的标签。之后需要生成训练数据的lattice来用在下面的训练中,还需要对训练数据进行切块,还有构建音素级别的语音模型以及解码图来用于下面的训练。这一切都准备好之后,就可以开始chain model的训练了。
4. kaldi中的训练流程简述
下面以kaldi中的egs/aishell2/s5为例,简要介绍整个chain model训练测试的操作流程.
4.1 训练脚本概览
训练脚本的主入口在run.sh中,主体代码如下:
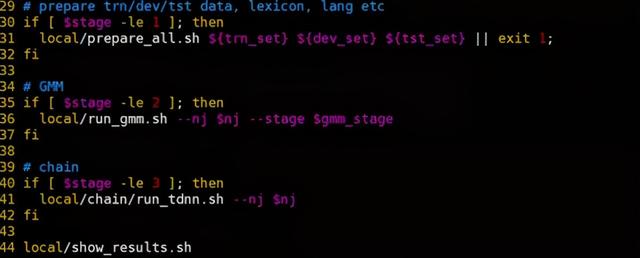
可以看到主要分为三部分,第一部分是数据准备模块,由local/prepare_all.sh脚本来执行;第二部分是GMM-HMM训练模块,由local/run_gmm.sh执行;第三部分是chain model的训练模块,由local/chain/run_tdnn.sh执行。下面会对着三个模块分别做介绍。
4.2 训练数据准备
那么在local/prepare_all.sh脚本中,第一部分是对发音词典的准备:

脚本默认使用DaCiDian作为发音词典,并且将其转为kaldi训练所需要的格式。我们采用的是公开发音词典和训练集相关发音词典的组合,并非默认词典。
第二部分则是对训练测试数据信息的准备,包括每条音频对应的说话人,每个说话人对应的音频,训练的标注文本以及音频的路径。

这里我们是采用自己的训练样本,没有运行这步代码,而是自己准备好kaldi所需要的格式,即有spk2utt,utt2spk,wav.scp,text文件。
接下来的代码会检查提供的发音词典情况,并且利用发音词典,生成解码图中的L.fst:

接下来的部分是语言模型的准备,是将语言模型训练语料生成为语言模型的标准格式:
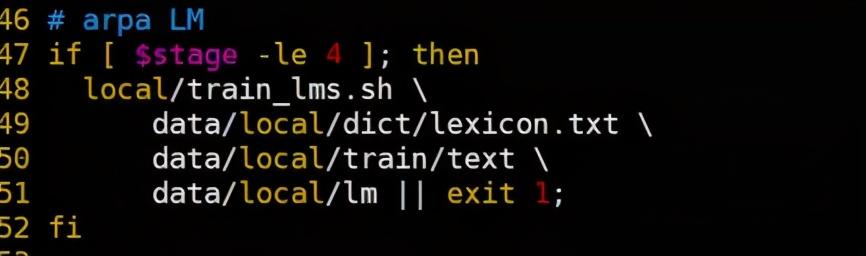
最后部分是根据语言模型和发音词典,组成解码图的LG.fst的过程:

4.3 HMM-GMM训练
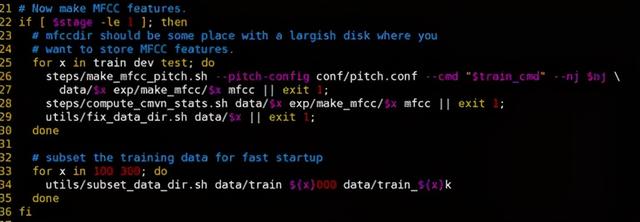
第一部分首先是计算训练测试音频的声学特征,这里是mfcc特征,同时会把训练集分成两个比较小的训练集,是因为模型的初始训练阶段会采用小参数量和小数据量的训练,之后慢慢增大参数量和数据量:
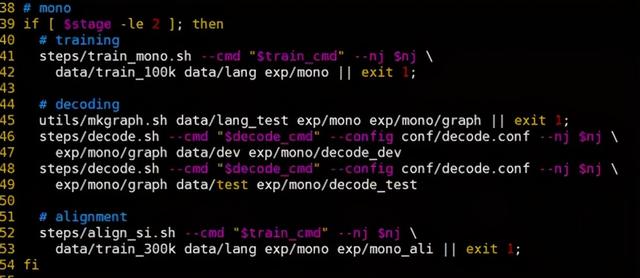
第二部分首先进行单音素声学模型训练,并在测试集上进行测试,最后还需要对下一部分的训练数据进行强制对齐:
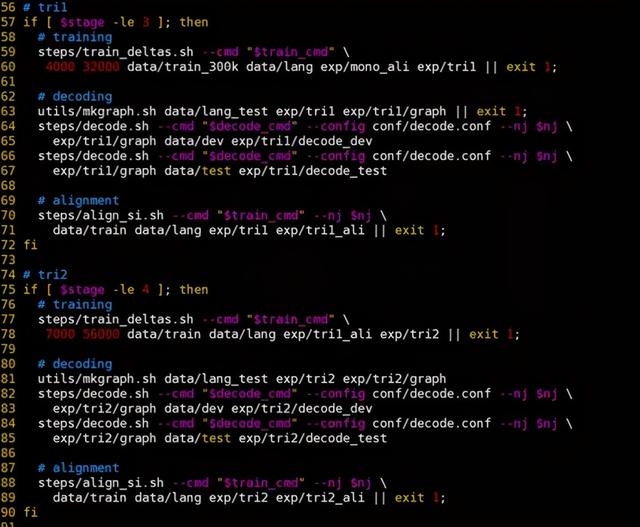
第三、四部分是三音素声学模型训练、测试,最终将所有训练数据进行强制对齐:
最后部分是进行LDA+MLLT适应性训练,这一步用处不大且耗时,我们在训练时去掉了这一步:
整个HMM-GMM过程的资源消耗情况如下,进程数为25:
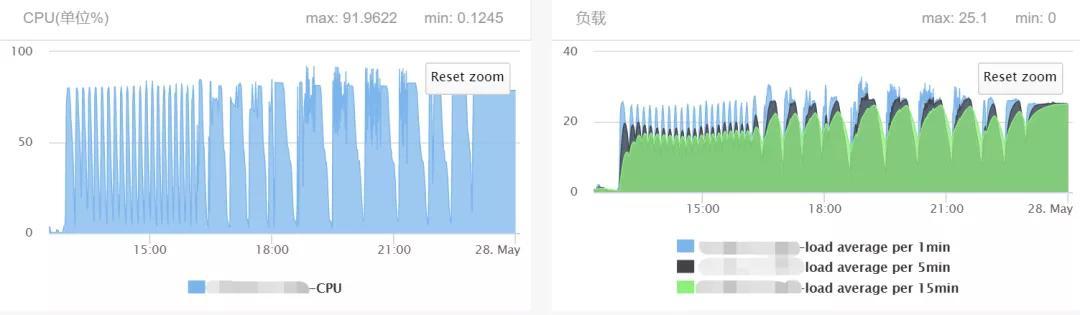
4.4 chain model 训练
第一部分首先是训练使用特征的计算,这里计算出了两种特征,一种是供TDNN模型训练的特征,还有一种是供ivector训练的特征。
第二部分是chain model训练的准备过程,会生成chain model所需要的lattice:

这部分耗时较长,因为需要把训练集都进行解码,在进程数为25的情况下,资源消耗如下:
第三部分是对模型文件拓扑结构的更改:
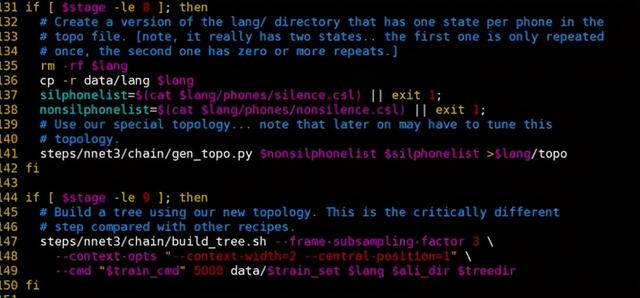
第四部分是对TDNN模型结构的定义:
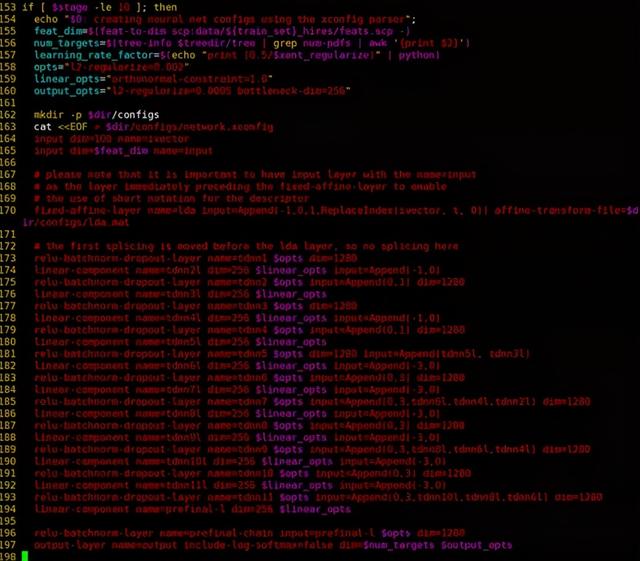
第五部分便是chain model的训练阶段,在训练开始时,需要把训练用到的所有样例写在磁盘上,之后再进入训练状态。
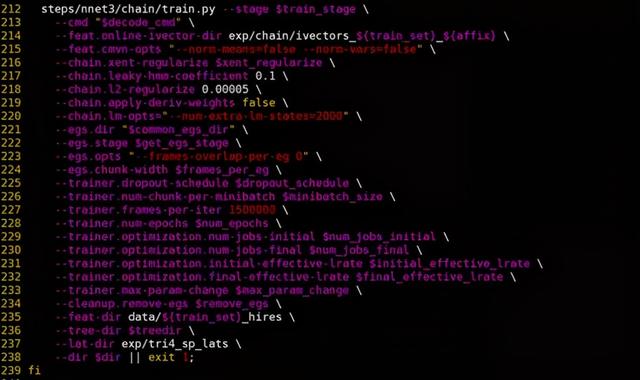
TDNN的训练过程消耗资源情况如下:
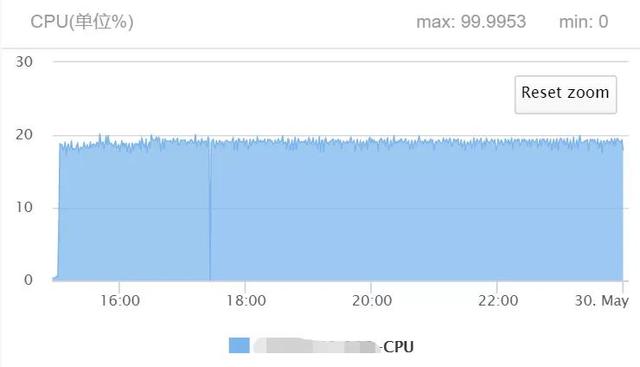
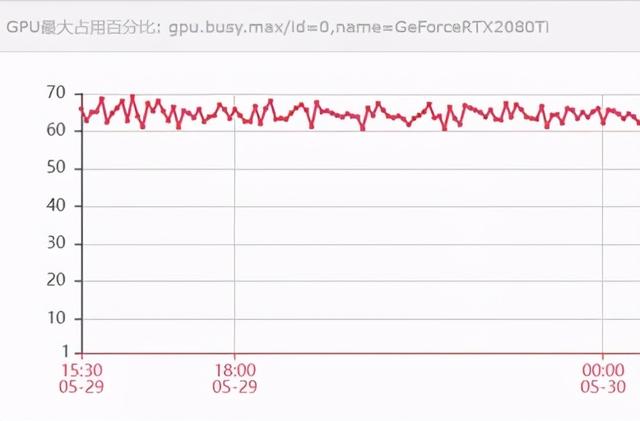
第六部分是生成解码图HCLG.fst的命令:

第七部分是测试阶段:
5. 不同声学模型的效果对比
为了展示文章中提到的几个声学模型的实际效果,我们用相同的训练集(混合了几个开源数据集),训练了不同的声学模型。训练的硬件配置为:2个CPU,32个逻辑核心,内存为251G,显卡是两张2080ti。CPU训练时开启的进程数为15个。最终测试结果如下:
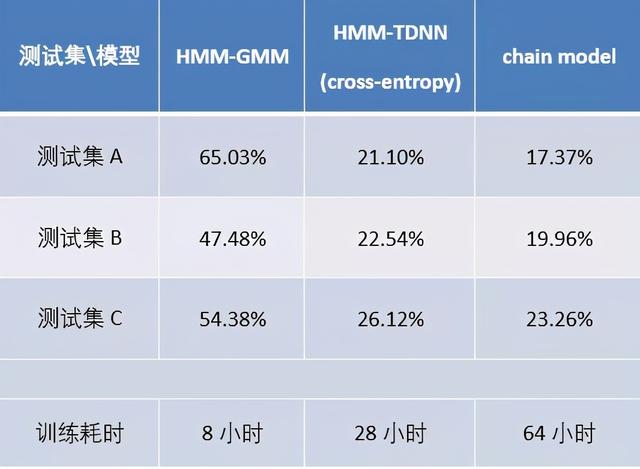
首先第一列是HMM-GMM系统的性能,第二列是用TDNN替代GMM作为发射概率建模,是HMM-DNN的一种,这里用TDNN是为了对比chain model的实验结果,因为chain model也用了相同的TDNN。首先可以看到无论是HMM-TDNN还是chain model,和GMM建模相比较,他们对性能都有非常大的提升,所以说DNN对GMM的替代,是革命性的。对比第二列第三列,我们在HMM-TDNN的基础之上,用chain model的一系列tricks,则能够把性能进一步提升。
总结
语音识别技术发展至今,形成了基于HMM和端对端的两大流派。本文在对chain model做介绍的同时,也对HMM流派的知识点和思想进行了阐述。chain model是HMM流派中比较重要的模型,他的思想既脱胎于HMM流派的经典模型同时又在各个方面做了很多的精妙的改进,对chain model的理解是理解HMM流派重要的一环。
参考文献:
[1]. Aubert – An overview of decoding techniques for large vocabulary continuous speech recognition – 2002
[2]. Dahl et al. – Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition – 2012
[3]. Rabiner – A tutorial on Hidden Markov Models and Selected Applications in speech recognition – 1989
[4]. Young, Odell, Woodland – Tree-based state tying for high accuracy acoustic modelling – 1994
[5]. Jeff.A – A Gentle Tutorial of the EM Algorithm and its Application to Parameter Estimation for Gaussian Mixture and Hidden Markov Models – 1998
[6]. Veselý et al. – Sequence-discriminative training of deep neural networks – 2013
[7]. Povey et al. – Purely sequence-trained neural networks for ASR based on lattice-free MMI – 2016
[8]. Peddinti, Povey, Khudanpur – A time delay neural network architecture for efficient modeling of long temporal contexts – 2015
部门简介:
58同城TEG技术工程平台群AI Lab,旨在推动AI技术在58同城的落地,打造AI中台能力,以提高前台业务人效和用户体验。
AI Lab目前负责的产品包括:智能客服、语音机器人、”灵犀”智能语音分析平台、智能写稿、CRM销售商机智能分配系统、语音识别、AI算法平台等,未来将持续加速创新,拓展AI应用。
部门详细介绍可点击:ailab.58.com
作者简介:
李咏泽:58同城TEG技术工程平台群AI Lab高级算法工程师
