
Storm安装教程

分布式实时流计算框架 Storm 广泛应用于实时日志分析、个性化推荐、实时监控等应用场景中。本教程介绍了如何在单机上安装、运行 Storm。本教程在 CentOS 6.4 系统、Storm 0.9.6 版本的环境中验证通过,理论上同样适用于 Ubuntu 等 Linux 系统。
本教程的具体运行环境如下:
CentOS 6.4Storm 0.9.6Java JDK 1.7ZooKeeper 3.4.6Python 2.6
CentOS中已默认安装了Python 2.6,我们还需要安装 JDK 环境以及分布式应用程序协调服务 Zookeeper。
安装Java环境
Storm 运行需要 Java 环境,可选择 Oracle 的 JDK,或是 OpenJDK,现在一般 Linux 系统默认安装的基本是 OpenJDK,如 CentOS 6.4 就默认安装了 OpenJDK 1.7。但需要注意的是,CentOS 6.4 中默认安装的只是 Java JRE,而不是 JDK,为了开发方便,我们还是需要通过 yum 进行安装 JDK,安装过程中会让输入 [y/N],输入 y 即可:
sudo yum install java-1.7.0-openjdk java-1.7.0-openjdk-devel
JRE和JDK的区别: JRE(Java Runtime Environment,Java运行环境),是运行 Java 所需的环境。JDK(Java Development Kit,Java软件开发工具包)即包括 JRE,还包括开发 Java 程序所需的工具和类库。
通过上述命令安装 OpenJDK,默认安装位置为 /usr/lib/jvm/java-1.7.0-openjdk(该路径可以通过执行 rpm -ql java-1.7.0-openjdk-devel | grep ‘/bin/javac’ 命令确定,执行后会输出一个路径,除去路径末尾的 “/bin/javac”,剩下的就是正确的路径了)。OpenJDK 安装后就可以直接使用 java、javac 等命令了。
接着需要配置一下 JAVA_HOME 环境变量,为方便,我们在 ~/.bashrc 中进行设置(扩展阅读: 设置Linux环境变量的方法和区别):
vim ~/.bashrc
在文件最后面添加如下单独一行(指向 JDK 的安装位置),并保存:
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk
如下图所示:

接着还需要让该环境变量生效,执行如下代码:
source ~/.bashrc # 使变量设置生效
设置好后我们来检验一下是否设置正确:
echo $JAVA_HOME # 检验变量值java -version$JAVA_HOME/bin/java -version # 与直接执行 java -version 一样
如果设置正确的话,$JAVA_HOME/bin/java -version 会输出 java 的版本信息,且和 java -version 的输出结果一样,如下图所示:

这样,Storm 所需的 Java 运行环境就安装好了。
安装 Zookeeper
本教程选择安装 zookeeper 最新稳定版(3.4.6),下载地址:http://mirrors.cnnic.cn/apache/zookeeper/stable/ 或 http://mirror.bit.edu.cn/apache/zookeeper/stable/ (打开网页,点击 Projects 下的 “zookeeper-3.4.6.tar.gz” 进行下载)。
下载后执行如下命令进行安装 zookeeper(将命令中 3.4.6 改为你下载的版本):
sudo tar -zxf ~/下载/zookeeper-3.4.6.tar.gz -C /usr/localcd /usr/localsudo mv zookeeper-* zookeepersudo chown -R hadoop ./zookeeper # 此处的hadoop为你的用户名
接着执行如下命令进行zookeeper配置:
cd /usr/local/zookeepermkdir tmpcp ./conf/zoo_sample.cfg ./conf/zoo.cfgvim ./conf/zoo.cfg
将当中的 dataDir=/tmp/zookeeper 更改为 dataDir=/usr/local/zookeeper/tmp 。接着执行:
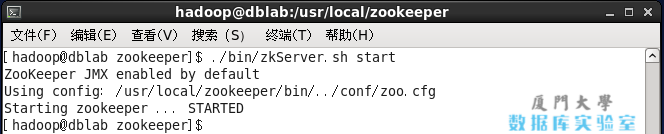
./bin/zkServer.sh start
若显示如下图则表示启动成功(显示 “Starting zookeeper … STARTED”):
安装Storm(单机)
本教程所使用的版本为 Storm 0.9.6 ,下载地址http://www.apache.org/dyn/closer.lua/storm/apache-storm-0.9.6/apache-storm-0.9.6.tar.gz。
下载后执行如下命令进行安装Storm:
sudo tar -zxf ~/下载/apache-storm-0.9.6.tar.gz -C /usr/localcd /usr/localsudo mv apache-storm-0.9.6 stormsudo chown -R hadoop ./storm # 此处的hadoop为你的用户名
接着执行如下命令进行Storm配置:
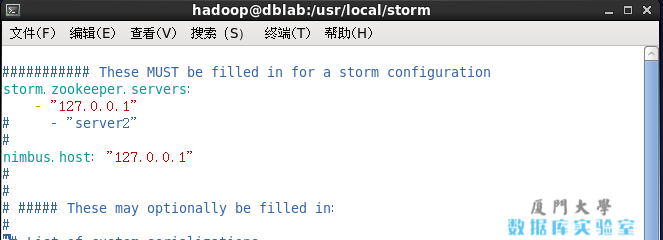
cd /usr/local/stormvim ./conf/storm.yaml
修改其中的 storm.zookeeper.servers 和 nimbus.host 两个配置项,即取消掉注释且都修改值为 127.0.0.1(我们只需要在单机上运行),如下图所示。
简单配置后就可以启动 Storm 了。执行如下命令启动 nimbus 后台进程:
./bin/storm nimbus
若启动成功则显示如下图内容:

启动 nimbus 后,终端被该进程占用了,不能再继续执行其他命令了。因此我们需要另外开启一个终端,然后执行如下命令启动 supervisor 后台进程:
# 需要另外开启一个终端/usr/local/storm/bin/storm supervisor
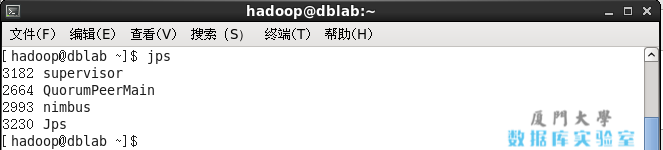
同样的,启动 supervisor 后,我们还需要开启另外的终端才能执行其他命令。另外,我们可以使用 jps 命令 检查是否成功启动,若成功启动会显示 nimbus、supervisor、QuorumPeeMain (QuorumPeeMain 是 zookeeper 的后台进程,若显示 config_value 表明 nimbus 或 supervisor 还在启动中),如下图所示。
启动Storm可能会遇到的问题如果启动 nimbus 时有显示 ERROR java.net.UnknownHostException 未知的名称或服务,或者启动 supervisor 后一会进程就中断了,则需要添加主机名的 ip 映射。执行 sudo vim /etc/hosts,增加一行 127.0.0.1 dblab,如下图所示。其中 dblab 为主机名,也就是终端的标题 hadoop@dblab:~,@与冒号中间的内容。

关闭Storm
之前启动的 nimbus 和 supervisor 占用了两个终端窗口,切换到这两个终端窗口,按键盘的 Ctrl+C 可以终止进程,终止后,也就相当于关闭了 Storm。
运行Storm实例-WordCount
Storm中自带了一些例子,我们可以执行一下 WordCount 例子来感受一下 Storm 的执行流程。执行如下命令:
/usr/local/storm/bin/storm jar /usr/local/storm/examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology
该程序是不断地取如下四句英文句子中的一句作为数据源,然后发送给 bolt 来统计单词出现的次数。
{ “the cow jumped over the moon”, “an apple a day keeps the doctor away”, “four score and seven years ago”, “snow white and the seven dwarfs”, “i am at two with nature”}
此外,该程序执行10秒后会自动关闭,可以看到程序执行过程中会输出非常多的信息(info 级别的日志输出,所以信息比较多),我们可以运行如下命令,使用 grep 命令对输出信息进行过滤,只输出我们所关心的内容–单词的实时统计信息(在这里我们只显示用于统计单词次数的 bolt 的输出信息)。
/usr/local/storm/bin/storm jar /usr/local/storm/examples/storm-starter/storm-starter-topologies-0.9.6.jar storm.starter.WordCountTopology | grep ‘Thread-[0-9]*-count’
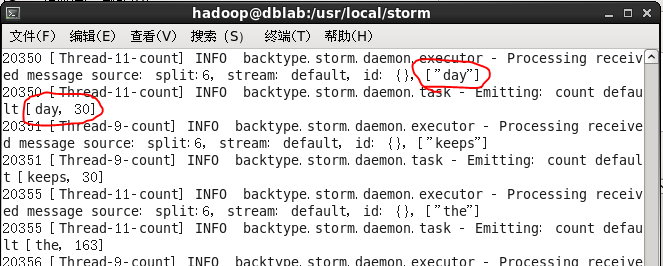
输出的结果如下图,一次处理会输出两条信息,一是显示接收到的数据(单词[“day”]),二是输出该单词当前总的出现次数([day, 30],表示当前”day”已出现了30次)。
更加具体的执行流程可以查看 WordCount 的代码(文件位置: /usr/local/storm/examples/storm-starter/src/jvm/storm/starter/WordCountTopology.java),代码不难理解。
至此,Storm 的安装、运行就介绍完毕了。Storm 官方提供了一个很好的入门代码 Storm starter,建议学习一下使用Maven编译运行Storm入门代码。













