
CUDA该怎么玩CUDA编程入门极简教程
作者 | DoubleV0203 编辑 | 机器学习算法工程师
点击下方卡片,关注“自动驾驶之心”公众号
ADAS巨卷干货,即可获取
点击进入→自动驾驶之心【全栈算法】技术交流群
后台回复【CUDA】获取CUDA实战书籍!
前 言
2006年,NVIDIA公司发布了CUDA(http://docs.nvidia.com/cuda/),CUDA是建立在NVIDIA的CPUs上的一个通用并行计算平台和编程模型,基于CUDA编程可以利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难题。近年来,GPU最成功的一个应用就是深度学习领域,基于GPU的并行计算已经成为训练深度学习模型的标配。目前,最新的CUDA版本为CUDA 9。
GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device),如下图所示。

基于CPU+GPU的异构计算. 来源:Preofessional CUDA® C Programming
可以看到GPU包括更多的运算核心,其特别适合数据并行的计算密集型任务,如大型矩阵运算,而CPU的运算核心较少,但是其可以实现复杂的逻辑运算,因此其适合控制密集型任务。另外,CPU上的线程是重量级的,上下文切换开销大,但是GPU由于存在很多核心,其线程是轻量级的。因此,基于CPU+GPU的异构计算平台可以优势互补,CPU负责处理逻辑复杂的串行程序,而GPU重点处理数据密集型的并行计算程序,从而发挥最大功效。

基于CPU+GPU的异构计算应用执行逻辑. 来源:Preofessional CUDA® C Programming
CUDA是NVIDIA公司所开发的GPU编程模型,它提供了GPU编程的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序。CUDA提供了对其它编程语言的支持,如C/C++,Python,Fortran等语言,这里我们选择CUDA C/C++接口对CUDA编程进行讲解。开发平台为Windows 10 + VS 2013,Windows系统下的CUDA安装教程可以参考这里http://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows/index.html
1
CUDA编程模型基础
在给出CUDA的编程实例之前,这里先对CUDA编程模型中的一些概念及基础知识做个简单介绍。CUDA编程模型是一个异构模型,需要CPU和GPU协同工作。在CUDA中,host和device是两个重要的概念,我们用host指代CPU及其内存,而用device指代GPU及其内存。CUDA程序中既包含host程序,又包含device程序,它们分别在CPU和GPU上运行。同时,host与device之间可以进行通信,这样它们之间可以进行数据拷贝。典型的CUDA程序的执行流程如下:
分配host内存,并进行数据初始化;
分配device内存,并从host将数据拷贝到device上;
调用CUDA的核函数在device上完成指定的运算;
将device上的运算结果拷贝到host上;
释放device和host上分配的内存。
上面流程中最重要的一个过程是调用CUDA的核函数来执行并行计算,kernel(http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#kernels)是CUDA中一个重要的概念,kernel是在device上线程中并行执行的函数,核函数用__global__符号声明,在调用时需要用来指定kernel要执行的线程数量,在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
由于GPU实际上是异构模型,所以需要区分host和device上的代码,在CUDA中是通过函数类型限定词开区别host和device上的函数,主要的三个函数类型限定词如下:
__global__:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
__device__:在device上执行,仅可以从device中调用,不可以和__global__同时用。
__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
要深刻理解kernel,必须要对kernel的线程层次结构有一个清晰的认识。首先GPU上很多并行化的轻量级线程。kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次。线程两层组织结构如下图所示,这是一个gird和block均为2-dim的线程组织。grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺省值初始化为1。因此grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构,对于图中结构(主要水平方向为x轴),定义的grid和block如下所示,kernel在调用时也必须通过执行配置(http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#execution-configuration)来指定kernel所使用的线程数及结构。
dim3 grid(3, 2); dim3 block(4, 3); kernel_fun>(prams…);

所以,一个线程需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识,它们都是dim3类型变量,其中blockIdx指明线程所在grid中的位置,而threaIdx指明线程所在block中的位置,如图中的Thread (1,1)满足:
threadIdx.x = 1threadIdx.y = 1blockIdx.x = 1blockIdx.y = 1
一个线程块上的线程是放在同一个流式多处理器(SM)上的,但是单个SM的资源有限,这导致线程块中的线程数是有限制的,现代GPUs的线程块可支持的线程数可达1024个。有时候,我们要知道一个线程在blcok中的全局ID,此时就必须还要知道block的组织结构,这是通过线程的内置变量blockDim来获得。它获取线程块各个维度的大小。对于一个2-dim的block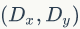 ,线程(x,y)的ID值为
,线程(x,y)的ID值为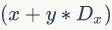 ,如果是3-dim的block
,如果是3-dim的block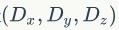 ,线程(x,y,z)的ID值为
,线程(x,y,z)的ID值为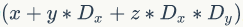 。另外线程还有内置变量gridDim,用于获得网格块各个维度的大小。
。另外线程还有内置变量gridDim,用于获得网格块各个维度的大小。
kernel的这种线程组织结构天然适合vector,matrix等运算,如我们将利用上图2-dim结构实现两个矩阵的加法,每个线程负责处理每个位置的两个元素相加,代码如下所示。线程块大小为(16, 16),然后将N*N大小的矩阵均分为不同的线程块来执行加法运算。
// Kernel定义__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) { int i = blockIdx.x * blockDim.x + threadIdx.x; int j = blockIdx.y * blockDim.y + threadIdx.y; if (i < N && j < N) C[i][j] = A[i][j] + B[i][j]; }int main() { ... // Kernel 线程配置 dim3 threadsPerBlock(16, 16); dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y); // kernel调用 MatAdd(A, B, C); ...}
此外这里简单介绍一下CUDA的内存模型,如下图所示。可以看到,每个线程有自己的私有本地内存(Local Memory),而每个线程块有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。此外,所有的线程都可以访问全局内存(Global Memory)。还可以访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)。内存结构涉及到程序优化,这里不深入探讨它们。
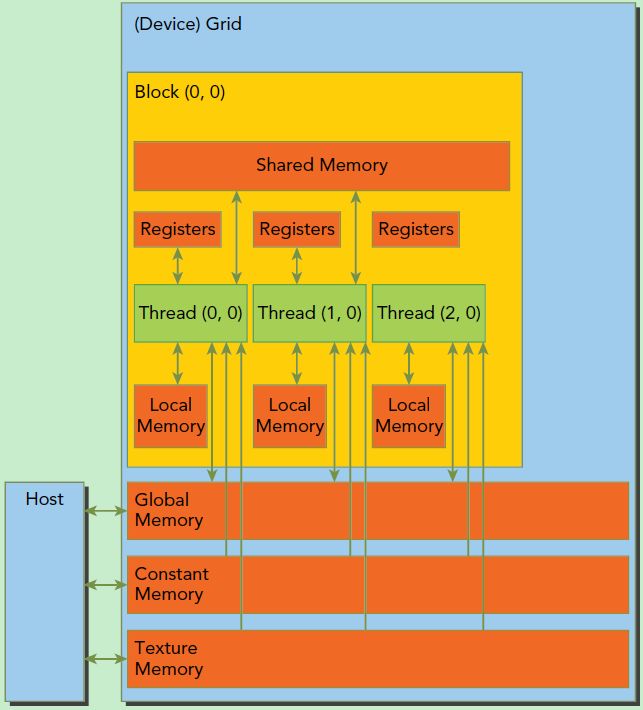
CUDA内存模型
还有重要一点,你需要对GPU的硬件实现有一个基本的认识。上面说到了kernel的线程组织层次,那么一个kernel实际上会启动很多线程,这些线程是逻辑上并行的,但是在物理层却并不一定。这其实和CPU的多线程有类似之处,多线程如果没有多核支持,在物理层也是无法实现并行的。但是好在GPU存在很多CUDA核心,充分利用CUDA核心可以充分发挥GPU的并行计算能力。GPU硬件的一个核心组件是SM,前面已经说过,SM是英文名是 Streaming Multiprocessor,翻译过来就是流式多处理器。SM的核心组件包括CUDA核心,共享内存,寄存器等,SM可以并发地执行数百个线程,并发能力就取决于SM所拥有的资源数。当一个kernel被执行时,它的gird中的线程块被分配到SM上,一个线程块只能在一个SM上被调度。SM一般可以调度多个线程块,这要看SM本身的能力。那么有可能一个kernel的各个线程块被分配多个SM,所以grid只是逻辑层,而SM才是执行的物理层。SM采用的是SIMT(链接:http://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#simt-architecture)(Single-Instruction, Multiple-Thread,单指令多线程)架构,基本的执行单元是线程束(wraps),线程束包含32个线程,这些线程同时执行相同的指令,但是每个线程都包含自己的指令地址计数器和寄存器状态,也有自己独立的执行路径。所以尽管线程束中的线程同时从同一程序地址执行,但是可能具有不同的行为,比如遇到了分支结构,一些线程可能进入这个分支,但是另外一些有可能不执行,它们只能死等,因为GPU规定线程束中所有线程在同一周期执行相同的指令,线程束分化会导致性能下降。当线程块被划分到某个SM上时,它将进一步划分为多个线程束,因为这才是SM的基本执行单元,但是一个SM同时并发的线程束数是有限的。这是因为资源限制,SM要为每个线程块分配共享内存,而也要为每个线程束中的线程分配独立的寄存器。所以SM的配置会影响其所支持的线程块和线程束并发数量。总之,就是网格和线程块只是逻辑划分,一个kernel的所有线程其实在物理层是不一定同时并发的。所以kernel的grid和block的配置不同,性能会出现差异,这点是要特别注意的。还有,由于SM的基本执行单元是包含32个线程的线程束,所以block大小一般要设置为32的倍数。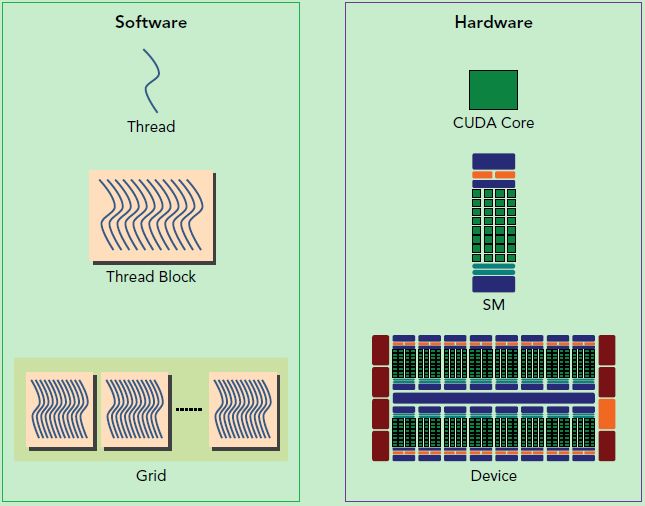
CUDA编程的逻辑层和物理层
在进行CUDA编程前,可以先检查一下自己的GPU的硬件配置,这样才可以有的放矢,可以通过下面的程序获得GPU的配置属性:
int dev = 0; cudaDeviceProp devProp; CHECK(cudaGetDeviceProperties(&devProp, dev)); std::cout













